TrOCR and Transformer-Based Reading for Image-to-LaTeX Workflows
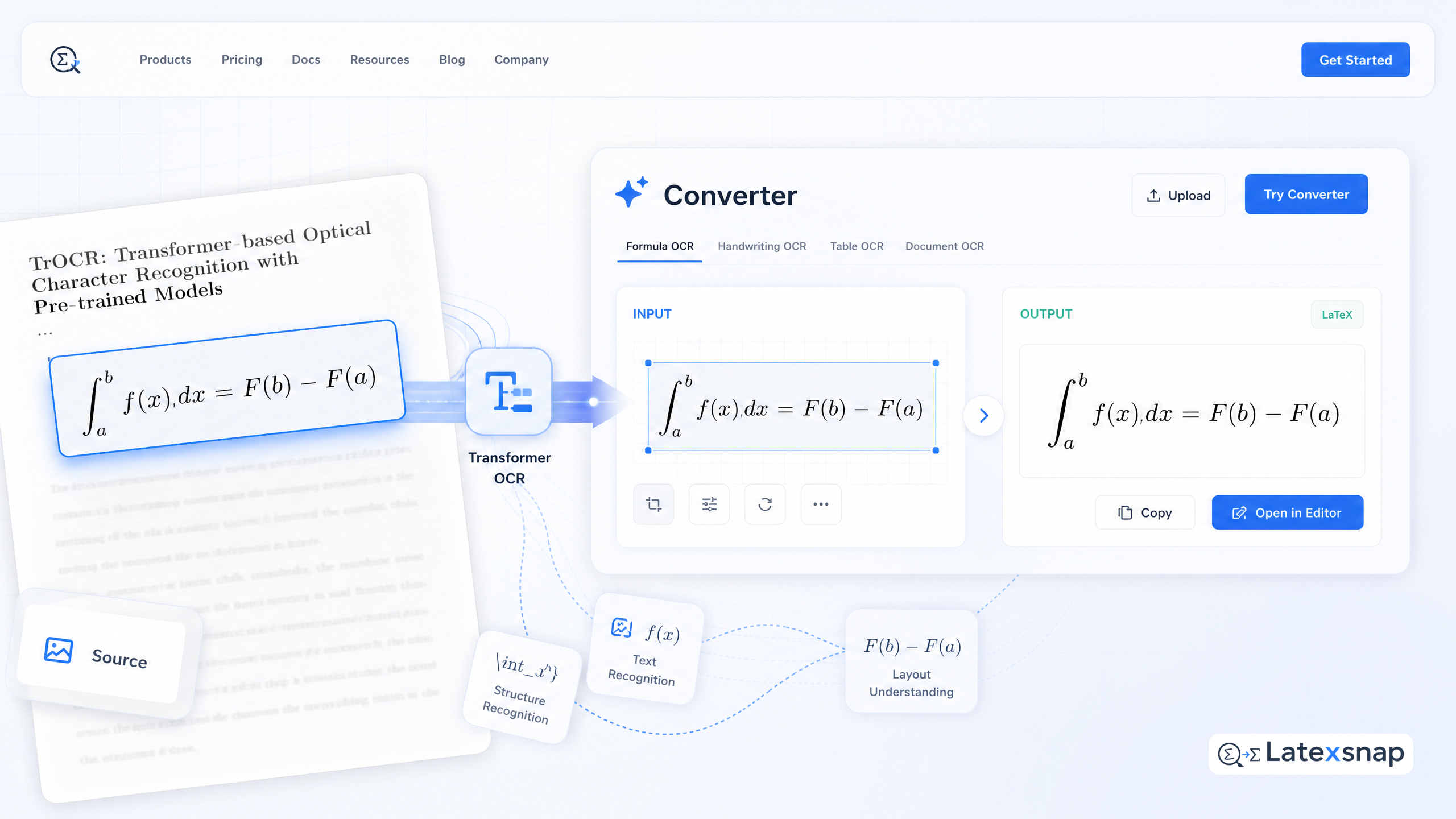
Transformer-based optical character recognition (OCR) has changed how we read noisy equation screenshots and scanned notes. This shift matters for image-to-LaTeX workflows because it improves the quality of raw text extraction before formula conversion. For a related next step on CRNN formula OCR, see CRNN Lessons for Turning Image Features into LaTeX Tokens.
What TrOCR Does
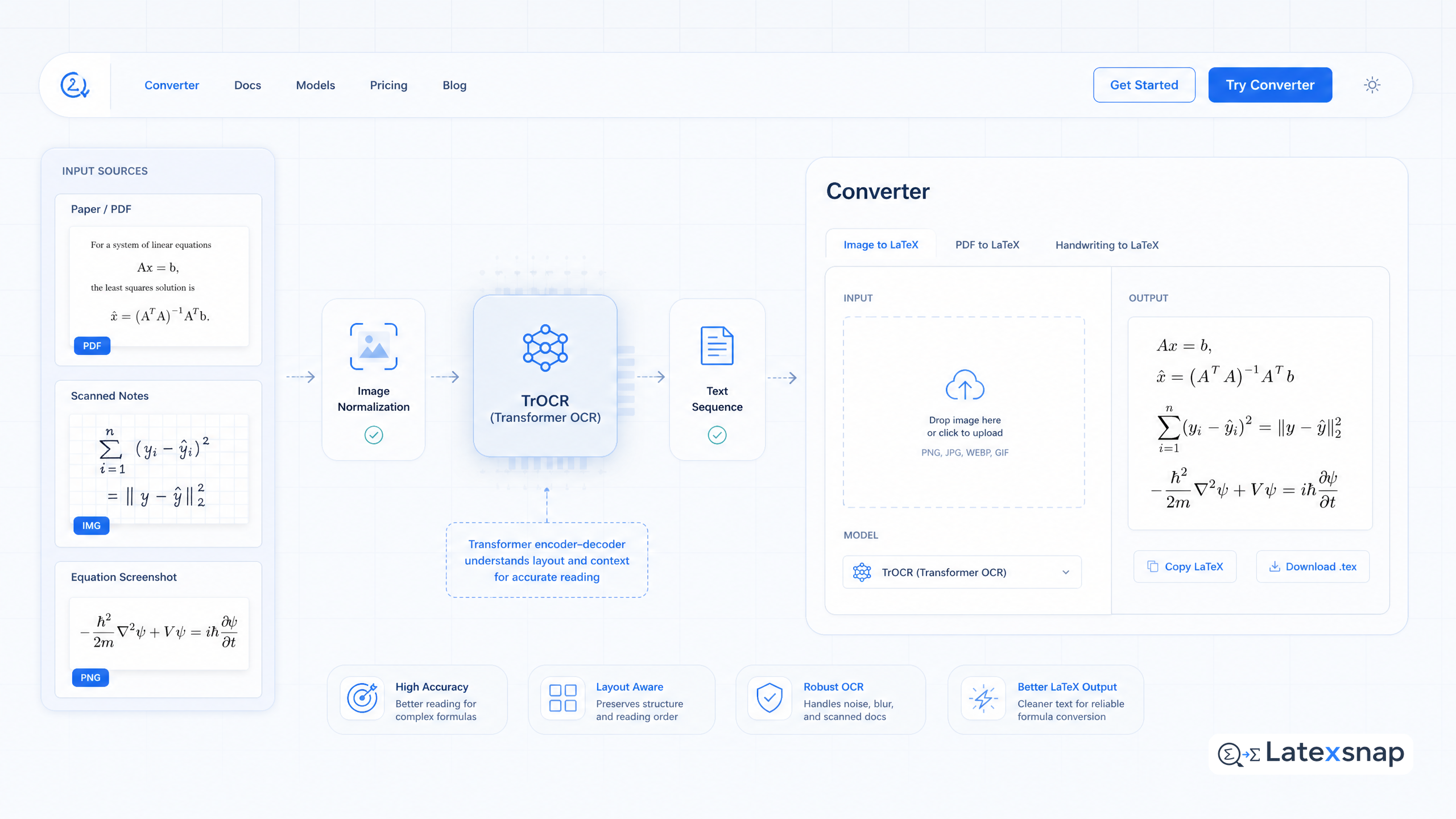
TrOCR is a transformer-based OCR model that uses pre-trained image and text transformers to recognize text in images. It achieves state-of-the-art results with a standard transformer-based encoder-decoder model that is convolution-free and does not rely on complex pre/post-processing steps.
The model first resizes the input text image into 384×384 pixels, then splits the image into a sequence of 16×16 patches which are used as the input to image transformers. Standard transformer architecture with the self-attention mechanism is leveraged on both encoder and decoder parts, where wordpiece units are generated as the recognized text from the input.
Why This Matters for Equation OCR
Traditional OCR models often struggle with mathematical notation, symbols, and complex formatting found in equations and formulas. Transformer-based models like TrOCR address these challenges through several key improvements:
Contextual Understanding: Transformers process entire sequences of text simultaneously, allowing them to understand context better than traditional character-by-character recognition methods. This is crucial for mathematical notation where symbols often have multiple meanings depending on their position and surrounding context.
Pre-trained Knowledge: By leveraging pre-trained image and text transformers, the model gains access to vast amounts of learned patterns from both visual and textual domains. This helps it recognize unfamiliar mathematical symbols and understand their relationships within equations. A useful companion workflow is Image to LaTeX workflow, especially when formula OCR workflow becomes part of the review process.
End-to-End Processing: Unlike traditional OCR systems that require multiple processing stages, transformer-based OCR can handle the entire recognition process in a single pass. This reduces errors that might occur during intermediate processing steps.
Practical Implications for LatexSnap Users
For users of LatexSnap, which converts equation images, handwriting, screenshots, and PDF formula snippets into editable LaTeX, transformer-based OCR offers several advantages:
Improved Accuracy: The contextual understanding provided by transformers leads to more accurate recognition of mathematical symbols and their relationships. This is particularly important for complex equations with nested operations and multiple variables.
Better Handling of Ambiguity: Mathematical notation often contains symbols that look similar but have different meanings. Transformers can use surrounding context to disambiguate these symbols more effectively than traditional methods. If you want to compare this with another practical angle, How to Write Fractions in LaTeX covers LaTeX editing workflow in more detail.
Faster Processing: The end-to-end nature of transformer-based OCR means faster conversion times, especially for longer equations or documents with many formulas.
Reviewing OCR Output
When working with transformer-based OCR for equation recognition, here are some practical tips for reviewing and improving output quality:
Crop Quality: Ensure that equation images are properly cropped and free from extraneous elements like page numbers, headers, or footers. High-quality input images lead to better recognition results. For teams extending this workflow, CTC and the Problem of Reading Unsegmented Formula Images is a natural follow-up for CTC formula OCR.
Ambiguous Symbols: Pay special attention to symbols that might be misrecognized, such as similar-looking characters (e.g., "l" vs "1", "O" vs "0", or mathematical symbols like "" vs ""). Manual review and correction can significantly improve accuracy.
LaTeX Structure: After conversion, review the generated LaTeX code to ensure proper structure and formatting. Transformers may occasionally produce incorrect nesting or formatting that needs manual adjustment.
Manual Review: Even with advanced OCR technology, manual review remains essential for catching errors and ensuring the final LaTeX output is accurate and well-formatted.
Looking Ahead
As transformer-based OCR continues to evolve, we can expect further improvements in equation recognition accuracy and speed. Models like TrOCR demonstrate the potential of combining pre-trained knowledge with transformer architectures to tackle challenging OCR tasks. When the document pipeline gets more complex, MDRNN and Why Two-Dimensional Context Matters in Formula OCR gives more context on two-dimensional OCR context.
For researchers, technical writers, and builders evaluating formula OCR workflows, understanding these advancements is crucial. The shift toward transformer-based approaches represents a significant step forward in making mathematical content more accessible and editable across different platforms and formats.
By staying informed about these developments and incorporating best practices for reviewing and refining OCR output, users can maximize the benefits of modern OCR technology in their LaTeX workflows.
Convert formulas faster