CTC and the Problem of Reading Unsegmented Formula Images

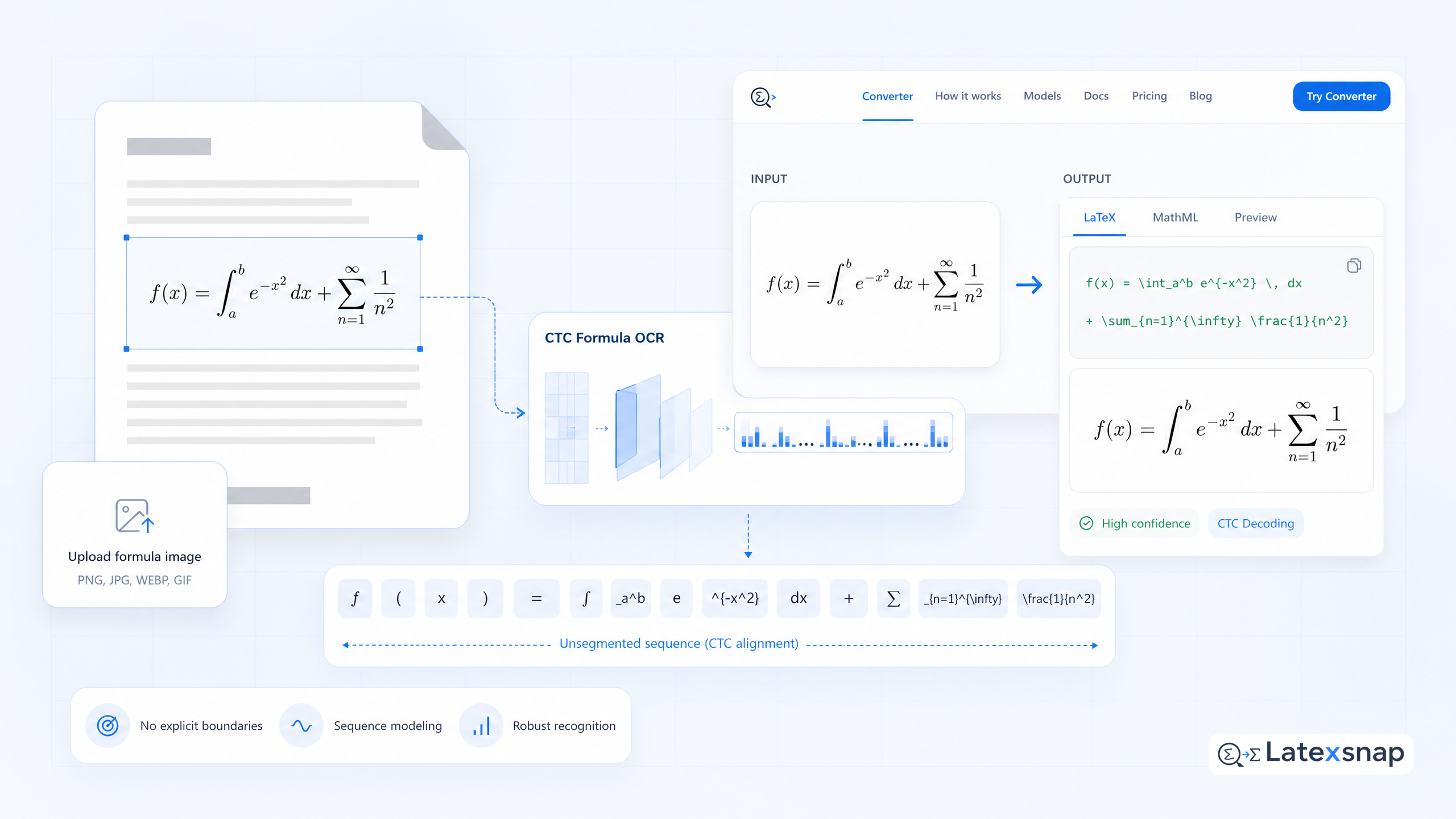
Formula OCR systems face a unique challenge: how to recognize mathematical expressions when the image provides no explicit token boundaries. Unlike text, where spaces and punctuation naturally separate words, equations are dense visual structures where symbols like integrals, fractions, and summations can span multiple lines without clear delimiters. This is where Connectionist Temporal Classification (CTC) becomes essential for modern equation recognition. For a related next step on CRNN formula OCR, see CRNN Lessons for Turning Image Features into LaTeX Tokens.
The Boundary Problem in Equation Recognition
Traditional optical character recognition relies on discrete character boundaries. In text, the space between "the" and "cat" tells the system where one word ends and another begins. Mathematical notation operates differently. Consider the expression:
0^ x2 e^(-x) dx
The integral sign spans vertically, the limits sit above and below, and the differential appears at the end. There are no spaces or punctuation marks to indicate where each component begins or ends. Without explicit boundaries, traditional segmentation approaches fail or require complex preprocessing that often introduces errors.
How CTC Solves Unsegmented Recognition
CTC addresses this boundary problem through a clever probabilistic framework. Instead of requiring the system to identify where each symbol begins and ends, CTC treats the entire sequence as a continuous stream of predictions. The model outputs a probability distribution over all possible symbols at each position, then uses a special "blank" symbol to represent regions without meaningful content.
For example, when processing the integral expression above, CTC might output a sequence like:
[blank] [integral] [0] [blank] [blank] [blank] [blank] [x] [2] [blank] [e] [(-] [x] [)] [blank] [d] [x] [blank]
The blank symbols effectively "skip" over the vertical span of the integral and other complex structures. During decoding, the system collapses consecutive blanks and identical adjacent symbols to recover the original expression.
Practical Implementation in Equation OCR
In practice, CTC-based systems achieve remarkable accuracy on challenging formula images. The approach works particularly well for: A useful companion workflow is MDRNN and Why Two-Dimensional Context Matters in Formula OCR, especially when two-dimensional OCR context becomes part of the review process.
- Multi-line expressions where symbols span across lines
- Complex fractions and radicals with nested structures
- Summations and products with extended limits
- Handwritten equations where spacing is inconsistent
The key advantage is that CTC doesn't require perfect image preprocessing or manual segmentation. It can handle variations in spacing, alignment, and symbol placement that would defeat traditional approaches.
LatexSnap's Integration of CTC
LatexSnap leverages CTC-based recognition to convert equation images into editable LaTeX with high accuracy. The system processes the image through a neural network trained on mathematical notation, applies CTC decoding to handle unsegmented sequences, and outputs properly formatted LaTeX code.
This approach enables LatexSnap to handle diverse input types:
- Screenshots of equations from textbooks or papers
- PDF formula snippets extracted from documents
- Handwritten notes with variable spacing and alignment
- Complex multi-line expressions spanning multiple lines
The result is a seamless conversion process that preserves the mathematical structure while making it editable in LaTeX editors.
Reviewing and Improving Equation OCR Results
Even with advanced CTC-based systems, equation OCR requires careful review. Here are practical tips for evaluating results:
Check crop quality: Ensure the image captures the complete expression without cutting off symbols or limits. Poor cropping can cause the system to misinterpret boundary conditions.
Verify ambiguous symbols: Some mathematical symbols have multiple interpretations depending on context. Review the system's interpretation of symbols like , , and to ensure they match the intended meaning.
Examine LaTeX structure: The generated LaTeX should maintain proper nesting and grouping. Check that fractions, integrals, and other complex structures use appropriate LaTeX commands.
Perform manual validation: For critical documents, manually verify the converted equation against the original. Pay special attention to:
- Superscripts and subscripts
- Integral limits and differentials
- Fraction bars and radical expressions
- Matrix and array structures
Future Directions in Formula Recognition
As equation recognition technology evolves, several promising developments are emerging:
- Hybrid approaches combining CTC with traditional segmentation methods
- Context-aware models that use surrounding text to disambiguate symbols
- Interactive systems that allow users to correct errors in real-time
- Multilingual support for equations in different notational systems
These advances will further improve the accuracy and usability of equation recognition tools, making them increasingly valuable for researchers, educators, and technical writers. For teams extending this workflow, Best Free LaTeX Tools for Students and Researchers in 2025 is a natural follow-up for LatexSnap workflow.
Conclusion
CTC represents a significant advancement in formula OCR, solving the fundamental challenge of recognizing mathematical expressions without explicit token boundaries. By treating equations as continuous sequences and using probabilistic decoding, CTC-based systems achieve remarkable accuracy on complex, unsegmented formula images. If you want to compare this with another practical angle, How to Convert Images to LaTeX Equations covers formula OCR workflow in more detail.
For anyone working with equation images, understanding CTC's approach provides valuable insight into modern OCR capabilities. Whether you're converting research papers, digitizing textbooks, or processing handwritten notes, CTC-based recognition offers a powerful solution to the equation OCR problem. When the document pipeline gets more complex, How to Keep Citations and LaTeX Equations Organized in Research Notes gives more context on citation and equation notes.
As the technology continues to evolve, we can expect even greater improvements in accuracy and usability, making mathematical notation more accessible and editable than ever before.
Convert formulas faster